Guard Against Transaction Loss with PostgreSQL Synchronous Replication
Crunchy Data recently released its latest version of the open source PostgreSQL Operator for Kubernetes, version 4.2. Among the various enhancements included within this release is support for Synchronous Replication within deployed PostgreSQL clusters.
As discussed in our prior post, the PostgreSQL Operator 4.2 release introduces distributed consensus based high-availability. For workloads that are sensitive to transaction loss, the Crunchy PostgreSQL Operator supports PostgreSQL synchronous replication.
Streaming Replication in PostgreSQL
When a high-availability PostgreSQL cluster is created using the PostgreSQL Operator, streaming replication is enabled to keep various replica servers up-to-date with the latest write-ahead log (WAL) records as they are generated on the primary database server. PostgreSQL streaming replication is asynchronous by default, which means if the primary PostgreSQL server experiences a failure and/or crashes, there is a chance some transactions that were committed may have yet to be replicated to the standby server, potentially resulting in data loss. The specific amount of data loss in this scenario varies, and is directly proportional to the replication delay at the time the failover occurs.
As an alternative to asynchronous replication, and more importantly to prevent data loss when a failure on the primary database server does occur, PostgreSQL offers synchronous replication. Synchronous replication provides the ability to ensure all changes made as the result of a transaction have been successfully written to the WAL on disk of not only the primary database server, but also to a replica server. This extends that standard level of durability offered by a transaction commit, specifically providing a level of protection referred to as 2-safe replication in computer science theory, in which data is written to two places (in this case both the primary database server and a replica) before reporting to the client that the commit was successful.
The following diagram depicts synchronous replication in PostgreSQL, specifically illustrating how data needs to be written to both the primary database and the synchronous replica before an acknowledgement of a successful commit is returned to the client.
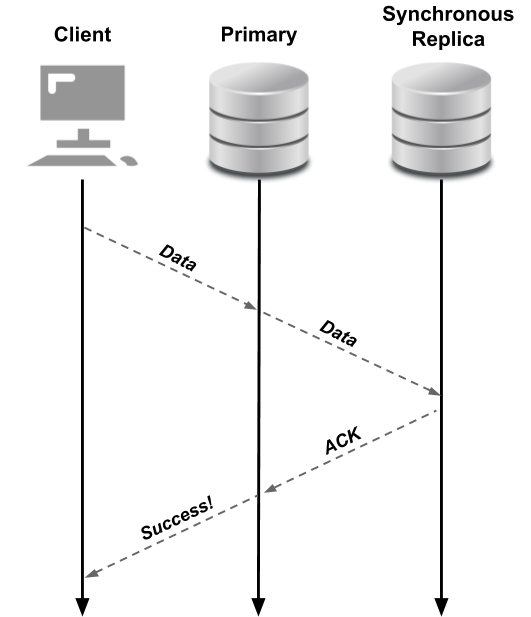
Synchronous Replication When Using the PostgreSQL Operator
When synchronous replication is enabled for a PostgreSQL cluster created using the PostgreSQL Operator, there are a few additional items to consider based on the default configuration for this feature. First and foremost, only the former primary, as well as the current synchronous replica, will be considered candidates for promotion in the event of a failure. This is to ensure that the only replica considered in the one that is known to be synchronous at the time of the failure, ensuring no data loss if/when that replica is promoted as the new primary.
This means that in the event that neither the original primary nor the current
synchronous replica can be promoted (e.g. if both are unhealthy), the database
will remain in a read-only state, even though other healthy (asynchronous)
replicas might be present in the cluster. Despite this, however, it is still
possible to manually failover to any available replica to re-enable writes to
the database, and accept any data loss that might result in favor of
availability (this can specifically be done using the pgo failover command
available with the pgo client).
Along these same lines, it should be noted that at any given time only a single
replica will be defined as the synchronous replica for the cluster within the
PostgreSQL configuration (postgresql.conf).
Therefore, while PostgreSQL itself allows more than one replica to be identified
as a viable candidate for synchronous replication using the
synchronous_standby_names configuration setting in the postgresql.conf file
(selecting a single replica at a time as the synchronous replica based on its
position in the list, and whether it is currently streaming data in real-time
from the primary), when using synchronous replication with the PostgreSQL
Operator only a single replica will ever be defined using this setting. This is
to ensure that at the time a failure occurs, the current synchronous node can be
properly identified as a candidate for promotion, as described above.
Finally, availability is still ultimately favored over durability. More specifically, if a valid synchronous replica is not available in the PostgreSQL cluster (e.g. if no replicas exist), then synchronous replication will be disabled, ensuring the database is still able to accept writes. This effectively allows two node clusters to be supported, since the database can continue to accept writes even after the primary is lost (in other words, assuming the original is primary lost and the only replica available has been promoted to be the new primary, there will be no longer be another replica available to act as the synchronous replica).
Therefore, in order to ensure synchronous replication remains enabled and therefore prevent data loss in the event of a failure, it is important to ensure there are a sufficient number of replicas within the PG cluster that can act as the synchronous replica if necessary. Furthermore, if should be noted that at any time the current synchronous replica is lost, the healthiest replica in the cluster will then be selected as the new synchronous replica, ensuring continued durability in the PostgreSQL cluster.
When Should You Select Synchronous Replication?
Synchronous Replication is useful for workloads that are sensitive to losing transactions, since as described above, PostgreSQL will not consider a transaction to be committed until it is committed to the current synchronous replica within the cluster. This provides a higher guarantee of data consistency and durability, namely a guarantee of the most up-to-date data will be available following a failover event.
However, it should be noted while synchronous replication is a powerful capability, it does come at the cost of performance. Specifically, when synchronous replication is enabled, a client no longer only has to wait for a transaction to be committed to the primary, but now must also wait for that transaction to be committed to the synchronous replica. This means that a connected client will have to wait longer for a transaction to be committed than if the transaction only had to be committed on the primary, such as seen when using asynchronous replication (as is enabled in a PostgreSQL database by default when utilizing streaming replication).
In the end, the specific workload being managed in the PostgreSQL cluster must be considered alongside the various elements described above to determine whether or not synchronous replication should be enabled.
Configuring Streaming Replication in the PostgreSQL Operator
Clusters managed by the Crunchy PostgreSQL Operator can be easily deployed with
synchronous replication enabled. For instance, when using the pgo client this
can be done by providing the --sync-replication flag with the
pgo create cluster command.
pgo create cluster hacluster --replica-count=2 --sync-replication
After running this command (and assuming the PostgreSQL Operator has been properly configured and installed in your Kubernetes cluster), a PostgreSQL cluster comprised of a primary database server and two replica servers will be created, with one of those replicas automatically selected as the current synchronous replica for the cluster. The other replica, despite initially streaming from the primary asynchronously, can later become the new synchronous replica in the event that either the current primary or synchronous replica is lost.
Example of Synchronous Replication Configuration and Failover
The following section will demonstrate how to properly create a PostgreSQL cluster with synchronous replication enabled, while also demonstrating the behavior of synchronous replication across various failover scenarios. This includes insight into how to verify that synchronous replication is enabled for a specific cluster, as well as how to obtain information about the state of synchronous replication for a cluster. Additionally, this section will also demonstrate the behavior of a PostgreSQL cluster with a single database server that has synchronous replication enabled.
In order to create a PostgreSQL Cluster that utilizes synchronous replication, it is first necessary to deploy the PostgreSQL Operator to your Kubernetes cluster. Instructions for the deploying the PostgreSQL Operator can be found here. Additionally, the steps below will utilize the PostgreSQL Operator pgo client to interact with the operator once deployed, and specific instructions for installing the pgo client can be found here.
Once the PostgreSQL Operator has been installed per the link above, a new
PostgreSQL cluster can be created utilizing the pgo create cluster command
shown in the previous section.
$ pgo create cluster hacluster --replica-count=2 --sync-replication
created Pgcluster hacluster
workflow id ebd16262-a96e-43f5-8066-34f4b6592f1c
At this point the PostgreSQL cluster will begin to initialize, which involves
bootstrapping the database on the primary database server, deploying and
initializing a pgBackRest repository for the cluster, and then creating an
initial pgBackRest backup. That backup will then be immediately utilized to
bootstrap and initialize the two replica servers. The pgo show cluster command
can be utilized to view the status of the cluster, specifically showing the
status of the current primary and any replicas.
$ pgo show cluster hacluster
cluster : hacluster (crunchy-postgres-ha:centos7-11.6-4.2.1)
pod : hacluster-767c844b87-fc5g8 (Running) on node01 (1/1) (primary)
pvc : hacluster
pod : hacluster-nrnx-dcbdccdc5-dxdwj (Running) on node01 (1/1)
(replica)
pvc : hacluster-nrnx
pod : hacluster-txmt-65d4f648d8-g8xg9 (Running) on node01 (1/1)
(replica)
pvc : hacluster-txmt
resources : CPU Limit= Memory Limit=, CPU Request= Memory Request=
storage : Primary=1G Replica=1G
deployment : hacluster
deployment : hacluster-backrest-shared-repo
deployment : hacluster-nrnx
deployment : hacluster-txmt
service : hacluster - ClusterIP (10.96.198.215)
service : hacluster-replica - ClusterIP (10.96.159.139)
pgreplica : hacluster-nrnx
pgreplica : hacluster-txmt
labels : name=hacluster deployment-name=hacluster pg-pod-anti-affinity= pgo-backrest=true pgo-version=4.2.1 sync-replication=true crunchy-pgha-scope=hacluster crunchy-pgbadger=false crunchy_collect=fals
e current-primary=hacluster pg-cluster=hacluster pgouser=pgoadmin workflowid=ebd16262-a96e-43f5-8066-34f4b6592f1c archive-timeout=60 autofail=true
Once the primary and all replica database servers are up and running, the Distributed Configuration Store (DCS) for the hacluster PostgreSQL cluster within the Kubernetes environment (as utilized into manage consistent configuration and state across all database servers in the highly-available PostgreSQL cluster) can be inspected to verify that synchronous replication is enabled.
Since the DCS is comprised of various Kubernetes configMaps, the kubectl
command line tool will be utilized here, specifically to inspect the
hacluster-config configMap. This configMap represents the portion of the DCS
that tracks and stores the current PostgreSQL and HA configuration for the
PostgreSQL cluster:
$ kubectl get configmap hacluster-config -o yaml
apiVersion: v1
kind: ConfigMap
metadata:
annotations:
config: '{"postgresql":{"parameters":{"archive_command":"source
/tmp/pgbackrest_env.sh
&& pgbackrest archive-push \"%p\"","archive_mode":true,"archive_timeout":60,"log_directory":"pg_log","log_min_duration_statement":60000,"log_statement":"none","max_wal_senders":6,"shared_buffers":"128MB",
"shared_preload_libraries":"pgaudit.so,pg_stat_statements.so",**"synchronous_commit":"on"**,**"synchronous_standby_names":"*"**,"temp_buffers":"8MB","unix_socket_directories":"/tmp,/crunchyadm","work_mem":"4MB"},"recov
ery_conf":{"restore_command":"source
/tmp/pgbackrest_env.sh && pgbackrest archive-get %f \"%p\""},"use_pg_rewind":true,"use_slots":false},**"synchronous_mode":true**}'
Within the above output (which has been truncated for brevity to only display the config annotation containing the cluster configuration), the following settings indicate that synchronous replication has been enabled:
"synchronous_commit":"on""synchronous_standby_names":"\*""synchronous_mode":true
With the synchronous replication configuration enabled and verified, the DCS can
again be inspected to identify the current synchronous replica within the
cluster. However this time instead of inspecting the hacluster-config
configMap, another portion of the DCS, i.e. the hacluster-sync configMap, will
be inspected instead. This configMap is generated on a per-cluster basis anytime
synchronous replication is enabled, and as shown in the output below, tracks the
pod acting as the current synchronous replica within the PostgreSQL cluster,
specifically using the sync_standby annotation:
$ kubectl describe configmap hacluster-sync
Name: hacluster-sync
Namespace: pgouser1
Labels: crunchy-pgha-scope=hacluster
vendor=crunchydata
Annotations: leader: hacluster-767c844b87-fc5g8
sync_standby: hacluster-nrnx-dcbdccdc5-dxdwj
Data
====
Events: <none>
As can be seen above the, pod hacluster-nrnx-dcbdccdc5-dxdwj is currently
acting as the synchronous replica for the cluster. Additionally, by looking at
the PostgreSQL configuration for the primary database server, it is also
possible to verify that the same replica server has been configured within the
postgresql.conf file as the synchronous replica, specifically using the
synchronous_standby_names configuration setting (please be sure to replace the
pod name in the command below with the name of the current primary pod within
your local cluster):
$ kubectl exec -it hacluster-767c844b87-fc5g8 -- \ cat
/pgdata/hacluster/postgresql.conf | \ grep synchronous_standby_names
synchronous_standby_names = '"hacluster-nrnx-dcbdccdc5-dxdwj"'
Now that the current synchronous replica has been identified, some failure
scenarios can be demonstrated. For the first failure scenario, the existing
synchronous replica will be deleted, which will result in the other replica
server in the cluster transitioning from an asynchronous replica into a
synchronous replica. In order to simulate this behavior, the Kubernetes
deployment for the synchronous replica will be scaled down to 0 using kubectl,
which will effectively destroy the pod containing the synchronous replica.
However, in order to scale down the cluster, it is first necessary to identify
the name of the deployment associated with the current synchronous replica pod,
specifically by inspecting the deployment-name label in the pod:
$ kubectl describe pod hacluster-nrnx-dcbdccdc5-dxdwj | \
grep deployment-name
deployment-name=hacluster-nrnx
As the above output shows, the name of the current Kubernetes deployment
associated with the synchronous replica pod is hacluster-nrnx. Therefore, with
the deployment name identified, it is now possible to scale down the deployment
and remove the synchronous replica:
$ kubectl scale deployment hacluster-nrnx --replicas=0
deployment.apps/hacluster-nrnx scaled
At this point the synchronous replica pod will be terminated and a new replica
will be identified and selected as the the new synchronous replica. Being that
the only other replica pod available at this point is
hacluster-txmt-65d4f648d8-g8xg9 (as could be seen when running the pgo show
command), it can be assumed that this replica (assuming it is still healthy)
will be selected as the new synchronous replica. By inspecting the
sync_standby annotation once again in the hacluster-sync configMap, it is
possible to verify that this is indeed the case:
$ kubectl describe configmap hacluster-sync | \
grep sync_standby
sync_standby: hacluster-txmt-65d4f648d8-g8xg9
At this point the PostgreSQL cluster should have a primary database server, along with a single replica server that is acting as a synchronous replica.
Now that the loss of the active synchronous replica has been demonstrated,
another failure scenario will be simulated to demonstrate the behavior of a
PostgreSQL cluster when the primary database server is lost and synchronous
replication is enabled in the cluster. However, first the cluster can be quickly
scaled back up to its original size to ensure there is at least one other
replica to act as a synchronous replica in the event that one of the other
database servers in the cluster is lost. Using kubectl, the Kubernetes
deployment previously scaled down to 0 replicas, can now once again be scaled
back up to a single replica:
$ kubectl scale deployment hacluster-nrnx --replicas=1
deployment.apps/hacluster-nrnx scaled
As a result of the command above, the replica previously removed will be
initialized, and will again join the PostgreSQL cluster as a replica. Since this
test will be demonstrating the loss of a primary database, some data can be
added to the database prior to simulating the failover, providing a dataset that
can then be validated on the new primary following the failover. This will be
done by using the kubectl exec command to access psql within the primary
database container, and then execute a SQL command to create and populate new
table within the database (the pgo show cluster command can be utilized to
identify the primary database pod):
$ kubectl exec -i hacluster-767c844b87-fc5g8 -- psql << EOF
CREATE TABLE mytable AS
SELECT * FROM generate_series(1, 10000) as id,
md5(random()::text) as data;
EOF
SELECT 10000
With the table above created (and assume both replicas are now online), a
failure on the primary database server can be simulated. This will be done by
once again using kubectl exec to access the primary database pod, only this
time a command will be run to delete the PostgreSQL PGDATA directory:
kubectl exec hacluster-767c844b87-fc5g8 -- bash -c 'rm -rf /pgdata/hacluster/*'
With the contents of the PGDATA directory on the primary deleted, a failover
to the synchronous replica will occur. Using the pgo show cluster command it
is possible to verify that the new primary is indeed the replica that was acting
as the synchronous replica at the time of the failure. Based on the steps above,
the current synchronous replica at the time of the failure for this example was
hacluster-txmt-65d4f648d8-g8xg9, and the pgo show cluster command verifies
that this database server has been promoted to be the new primary:
$ pgo show cluster hacluster | grep "(primary)"
pod : hacluster-txmt-65d4f648d8-g8xg9 (Running) on node01 (1/1)
(primary)
Further, by running a quick psql command on the new primary it is possible to
verify that the data previously inserted into the database does still exist
following the failover (please note the pod name in the command below is the pod
name for the new primary):
$ kubectl exec hacluster-txmt-65d4f648d8-g8xg9 -- \
psql -c 'select count(id) FROM mytable'
count
-------
10000
(1 row)
Additionally, another replica will now be chosen as the synchronous replica for
the cluster, and the synchronous_standby_names PostgreSQL setting for the new
primary will now point to that replica as well (please note that the PGDATA
directory in the command below reflects the name of the new primary):
$ kubectl describe configmap hacluster-sync | grep sync_standby
sync_standby: hacluster-xwwu-c98c4b8bd-zld54
$ kubectl exec hacluster-txmt-65d4f648d8-g8xg9 -- \
cat /pgdata/hacluster-txmt/postgresql.conf | \
grep synchronous_standby_names
synchronous_standby_names = '"hacluster-xwwu-c98c4b8bd-zld54"'
For one final test, a new cluster called hacluster2 will be created that
contains a primary and only a single replica (which will be the synchronous
replica). That replica will then be destroyed, demonstrating the behavior of a
single server cluster with synchronous replication enabled. To create the
hacluster2 cluster, run the following command:
pgo create cluster hacluster2 --replica-count=1 --sync-replication
Once the cluster is up and running, the name of the synchronous replica can be once again be identified by inspecting the DCS, as was previously done for cluster hacluster above. This includes first identifying the pod that contains the current synchronous replica:
$ kubectl describe configmap hacluster2-sync | \
grep sync_standby
sync_standby: hacluster2-tfro-57d77b7fcd-czvkg
And then obtaining the name of the replica by inspecting the replica-name
label that can be found on that pod.
$ kubectl describe pod hacluster2-tfro-57d77b7fcd-czvkg | \
grep replica-name
replica-name=hacluster2-tfro
With the name of the synchronous replica identified, it can now be removed. This
time this will be accomplished by scaling down the cluster using the
pgo scaledown command, which will permanently delete the replica and its
associated kubernetes resources (pods, deployments, configMaps, secrets, etc.):
$ pgo scaledown hacluster2 --target=hacluster2-tfro
WARNING: Are you sure? (yes/no): yes
deleted Pgreplica hacluster2-tfro
Once the synchronous replica has been terminated, only a single server will remain in the PostgreSQL cluster, i.e. only the primary database server will remain. And and as previously discussed, despite the fact that synchronous replication has been enabled for the cluster, the database will still be able to accept writes. This can be shown by again adding some data to the database:
$ kubectl exec -i hacluster2-6dfcc9c744-q9t7b -- psql << EOF
CREATE TABLE mytable AS
SELECT * FROM generate_series(1, 10000) as id,
md5(random()::text) as data;
EOF
SELECT 10000
Further, if the postgresql.conf file is inspected, specifically to view the
synchronous_standby_names setting that identifies the current synchronous
standby, there will not be a synchronous_standby_names setting present, which
means that synchronous replication has effectively been disabled for the
database:
kubectl exec hacluster2-6dfcc9c744-q9t7b -- \
cat /pgdata/hacluster2/postgresql.conf | \
grep synchronous_standby_names
However, despite the fact that synchronous replication is currently disabled in the database, it is still enabled within the cluster as a whole. In other words, as soon as a replica is added to the cluster, synchronous replication will once again be enabled. This can be seen by adding a new replica to the cluster as follows:
$ pgo scale hacluster2
WARNING: Are you sure? (yes/no): yes
created Pgreplica hacluster2-ltjm
Once the replica is initialized, it will then be selected as the synchronous
replica, and the synchronous_standby_names setting will once again be
populated in the postgresql.conf file with the proper name of the new
synchronous replica:
$ kubectl describe configmap hacluster2-sync | \
grep sync_standby
sync_standby: hacluster2-ltjm-7879c6dcb6-7fhbf
$ kubectl exec hacluster2-6dfcc9c744-q9t7b -- \
cat /pgdata/hacluster2/postgresql.conf | \
grep synchronous_standby_names
synchronous_standby_names = '"hacluster2-ltjm-7879c6dcb6-7fhbf"'
Conclusion
This concludes the demonstration of the new synchronous replication feature
included in version 4.2 of the PostgreSQL Operator. In order to cleanup the
Kubernetes cluster, both PostgreSQL clusters created above can now be deleted
using pgo delete cluster command. Please note that unless the --keep-data
and/or --keep-backups options are specified when running these commands, all
data associated with the clusters (e.g. PGDATA directories) will be removed.
pgo delete cluster hacluster hacluster2
In closing, the PostgreSQL Operator greatly facilitates the configuration of synchronous replication within a PostgreSQL cluster, providing an easy-to-use and effective solution for enabling this powerful PostgreSQL feature. With the ability to easily turn on synchronous replication for any PostgreSQL cluster, users now have the ability to ensure that any PostgreSQL workloads within their Kubernetes clusters that are sensitive to data loss are durable and resilient across failure scenarios.
This means guaranteeing that the latest data is always available in two places, i.e. a primary database server and a synchronous replica server, where it can then be made available in the event of a failure. Additionally, this demonstrates yet another way in which the PostgreSQL Operator can customize and tailor PostgreSQL database clusters according to specific workloads and requirements.
