The Answer is Postgres; The Question is How?
There is increasing consensus that Postgres is a great choice of database for a broad range of use cases. As our friends at RedMonk have said:
the answer is postgres, now what's the question again? ;-)
— Elon Mook (@monkchips) April 29, 2017
You have a number of good options for how to run Postgres: run it in VMs, as a managed service or bare metal. Benjamin Good, a Google Cloud Solutions Architect, wrote a helpful blog post of when to run databases on Kubernetes; a common question and increasingly popular and successful option.
So which deployment model is appropriate for you? As usual, it depends.
At Crunchy Data, we support customers who have made the choice for all of the above. That vantage point gives us some perspective on when you should choose which approach. Building on the Google Cloud framework, let's review the options and considerations.
Postgres on Virtual Machines: The "Old" Standard
The Google Cloud analysis describes this as the "Full Ops" option, "Where you take full responsibility for building your database, scaling it, managing reliability, setting up backups, and more," with a core trade-off between the level of effort to maintain the database against the flexibility associated with your choice of location for deployment (on-premise, public cloud, etc.).
Most Postgres users view running on VMs as a tried and true approach (though this wasn’t always the case). There are many tools for automating Postgres on VMs, enabling users to reduce the administrative level of effort. Automated or not, you are of course responsible for the database administration.
Often the choice of Postgres on VMs is most appropriate when you already have the necessary internal infrastructure and expertise to run databases and you want control over both your database and infrastructure. The decision is commonly driven by economies of scale. In the public cloud you may prefer VM-based Postgres deployments due to flexibility in version availability, configuration options and availability of extensions.
In these cases, Postgres on VMs provides the right balance of flexibility, control and investment.
Postgres on Kubernetes: Is Kubernetes Ready for Databases?
PostgreSQL on Kubernetes is a new option by database standards. Kubernetes provides many benefits for running applications, including efficiency, automation, or infrastructure abstraction. But what about running databases?
It is a common question of whether Kubernetes has matured to the point where it is ready for stateful workloads. My colleague Greg Smith recounts that it took VMs about five years of maturation before users could reliably run Postgres. By that time, following appropriate testing of their configuration, users could prove that their VM platform was sufficiently reliable to run a database. Has Kubernetes reached the maturity stage where you can reliably run databases on that platform?
The Cloud Native Computing Foundation (CNCF) Cloud Native Survey 2020 provides interesting data. The CNCF Survey reports that 55% of respondents are using stateful applications in containers in production.
Today, it isn’t just early adopters running Postgres on Kubernetes. Many Crunchy Data customers have successfully deployed Postgres on Kubernetes, and have been kind enough to talk about it.
While there were initially some rough edges in running Postgres on Kubernetes, it has come a long way since the early days. The Kubernetes ecosystem has evolved considerably since the days of "Petsets" and Third Party Resources with the evolution of the Operator model from CoreOS and the variety of storage options currently available to users.
Similar to VMs, with time Postgres admins are getting more comfortable running Postgres on Kubernetes. To help build that confidence, our team recently worked with Red Hat to validate Postgres containers on Kubernetes.
Postgres on Kubernetes: But Postgres?
The Google Cloud post describes databases on Kubernetes as "closer to the full-ops option," while indicating that "You do get some benefits in terms of the automation Kubernetes provides to keep the database application running." In the Google Cloud's analysis, the key decision point is whether the database has "Kubernetes-friendly features" or "Is there an operator project to help?"
We of course believe Postgres is a great database. Its core functionality is extended through a robust open source software ecosystem. With the right tools (like the Postgres Operator) and expertise, Postgres is Kubernetes friendly. Was it designed from scratch to work with cloud native primitives? No.? Does it work with cloud native primitives from continued development and evolution? Absolutely.
Kubernetes provides many interesting capabilities for running databases, particularly when coupled with an Operator. The ability to scale up nodes uniformly makes it easier to manage hardware for databases as they grow. Kubernetes features like node affinity and tolerations allow admins to make decisions about where Postgres instances are deployed. These tools combine to enable database workloads to benefit from high availability or specific hardware.
That said, running Kubernetes, and applications on Kubernetes, comes with its share of administrative requirements. Operators and tools such as Helm and Kustomize are all helpful in easing the administrative burden, but automation and orchestration associated with Kubernetes does not come for free.
In the context of Postgres, the question seems to boil down to whether a user values the benefits of Kubernetes sufficiently to sustain the incremental administration.
Fully Managed Postgres
What about fully managed database options for Postgres? As database workloads move to the cloud, managed services are an attractive option for deploying databases. Google Cloud describes this as the "low-ops choice" as the ‘managed service’ handles a number of the database administration tasks for you - including backups, patching and scaling.
Crunchy Data launched Crunchy Bridge to provide users with the best managed Postgres experience. By combining industry leading Postgres expertise, with extensive operational expertise running Postgres as a service, Crunchy Bridge provides users with the flexibility of Postgres control, Postgres extensions and dedicated Postgres support.
Managed Postgres also enables you to benefit from hands-on expertise from Crunchy Data Postgres engineers. As my colleague Craig likes to say, “Fully managed Postgres from Crunchy provides you with the benefit of the Crunchy Data engineers with decades of experience running large scale Postgres databases and database as a service. “ While many days you may not need this level of expertise to run Postgres, when you do, you can have confidence the scale we operate Postgres at has given us experience to effectively troubleshoot any problem with Postgres.
For users who are not interested in maintaining a database server, managed Postgres is a great option. And you still get the best part: Postgres
So what should you do?
Good news. Deciding to use Postgres is a great start, we like to think it’s the right start. As to how best to deploy it, you have a number of options.
To ensure users have a variety of Postgres options, Crunchy Data provides Crunchy High Availability PostgreSQL for VM based deployments, Crunchy PostgreSQL for Kubernetes complete with a mature Postgres Operator, and Crunchy Bridge, a managed Postgres service.
The analysis that we have seen is less of an either/or decision and more of a question of when and where. Similar to the hybrid cloud reality that enterprises of all sizes tend to use, Postgres users often choose some combination of these deployment models based upon their team requirements and organizational standards. The choice is less about deciding which model to use for all applications, and more about which choice to use for a given project.
For many projects, using a managed service works well if the use cases require a "set and forget" Postgres deployment. The choice between deploying Postgres on VMs and Kubernetes is less about a decision for more or less management or automation but rather based on whether a group is standardizing on Kubernetes.
Are you still wondering how you should deploy PostgreSQL? Let me offer a decision tree to help you:
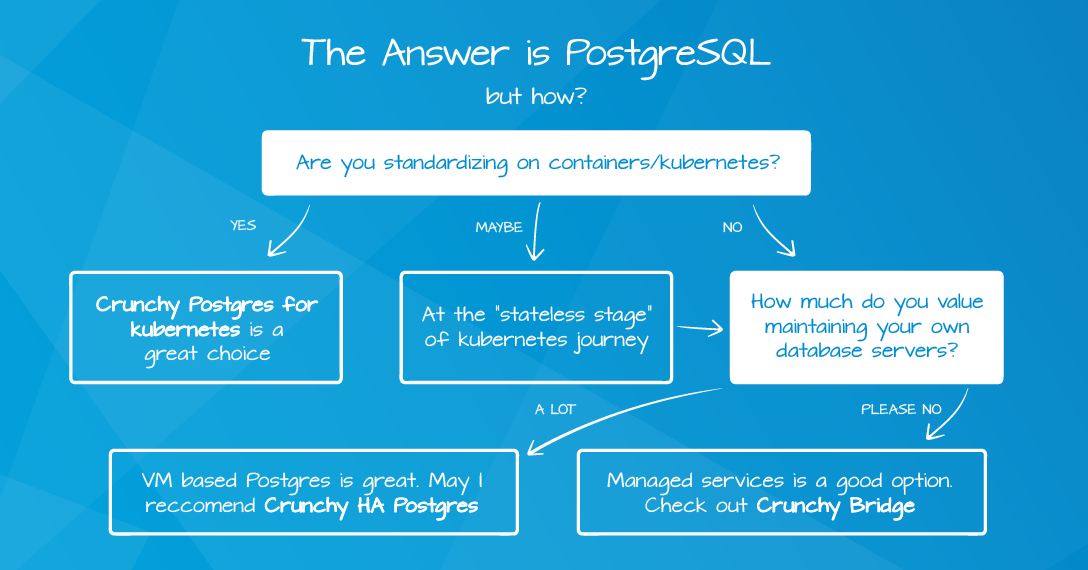
As with everything, each decision has trade offs but as long as you are starting with "The answer is Postgres," it is unlikely you'll get too far off the correct path. If you need help, Crunchy Data is here to assist.
