How to Perform Failover with the PostgreSQL Kubernetes Operator
Crunchy Data recently released version 2.6 of the PostgreSQL Kubernetes Operator, a powerful controller that follows the Kubernetes Operator pattern that enables users to provision and manage thousands of PostgreSQL databases at scale. We thought that we would demonstrate some of the features in this latest version over the next few weeks, which includes support for manual database failover, storage selection, node (or server) selection preference, and many goodies that make it easier to manage a large PostgreSQL cluster.
We will start with failover, an important concept for being able to maintain a high-availability database cluster.
Installation
In order to try out these examples, you will need to have the PostgreSQL Kubernetes Operator installed. You can find detailed installation instructions for version 2.6 here, including where to find packages containing the PostgreSQL Kubernetes Operator as well as a quickstart script that will perform a lot of the heavy lifting of installation and setup.
Configuring a production environment to utilize the PostgreSQL Kubernetes Operator is a large topic that is unfortunately out of scope for this article, but there are some instructions to help get you started with the PostgreSQL Operator project.
To perform the examples with a pre-existing cluster, we will use a cluster called sample that is created with the following command:
pgo create cluster sample
pgo scale sample --replica-count=2
Failover with the PostgreSQL Operator
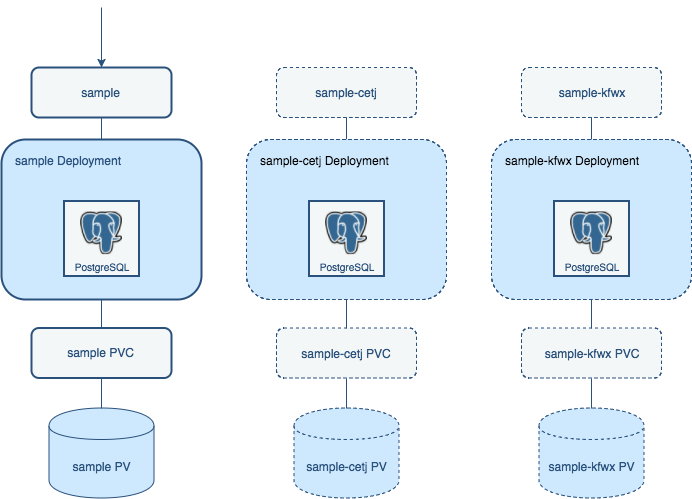
An essential feature of being able to maintain a high-availability database cluster is being able to fail over to a replica database should the primary database become inaccessible. When failing over from a primary database to a replica database, there are a few things you should keep in mind:
- Your chosen replica database is both accessible and can handle the writes that will be sent at it without causing significant performance degradation.
- Your primary is completely offline in order to avoid "multiple primaries" from being active (also known as the "split-brain" problem. The acronym "STONITH" has been frequently used to describe this process).
- Your application is able to connect and interact with the replica database after it becomes the primary.
The PostgreSQL Operator helps to simplify the failover process with the "failover" command which, after you select a replica, does the following behind the scenes:
- Destroys the current primary PostgreSQL instance to prevent the "split-brain" problem from occurring.
- Promotes the selected replica to begin accepting write queries.
- Re-label the selected replica instance to use the primary service labels. This causes all writes (and based on whether or not you're using a load balancer, a portion of to all reads) to now go to the promoted instance.
- Provision a new replica to replace the old replica instance.
The process of destroying the old primary and promoting the new primary takes only a matter of seconds. Provisioning the new replica can take some time depending on how large your data set is.
This sounds a lot of steps, which begs the question, how can this be accomplished with the PostgreSQL Operator?
First, you should determine which of your replicas are available to fail over to. This can be accomplished with the following command:
pgo failover sample --query
which returns a list of replcias:
Failover targets include:
sample-cetj
sample-kfwx
To perform failover, you simply execute:
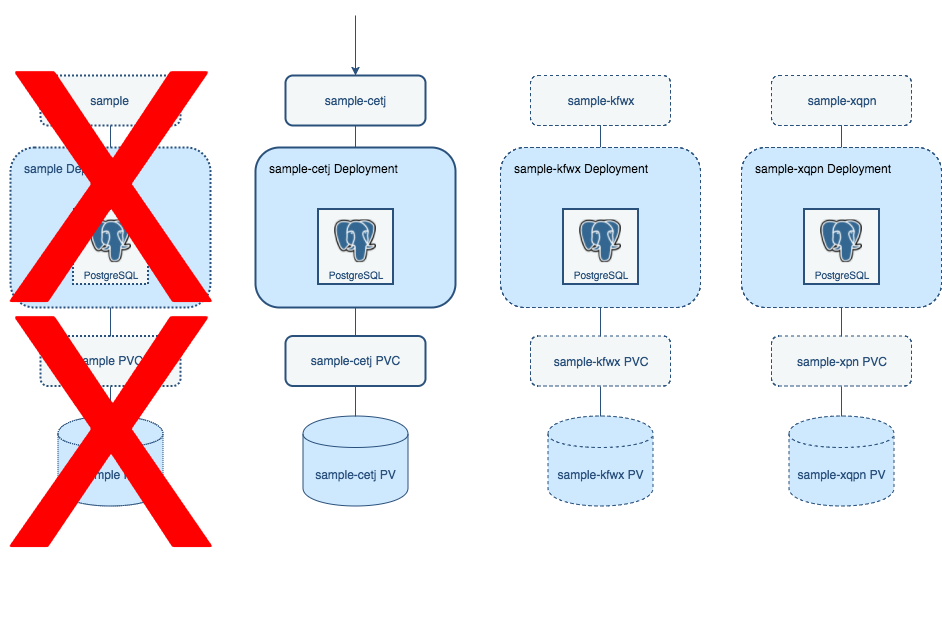
pgo failover sample --target=sample-cetj
where sample-cetj is the name of your failover target. That's it: the PostgreSQL Kubernetes Operator handles the rest of the failover operation!
If you want to check on how the status of the failover, you can run the following command:
kubectl get pgtasks sample-failover -o yaml
where you can replace sample with the name of your cluster.
Once the failover is complete, you will see that the replica is promoted to become the primary, and there is a new replica pod now available.
If you need to failover again in the future, you will need to clear out the pgtask that was used to run the previous failover, which can be handled with the following command:
kubectl delete pgtasks sample-failover
And that's it - you can now manage failover with the PostgreSQL Kubernetes Operator!
